Advanced artificial intelligence (AI) and convolutional neural network (CNN) technology has made automatic detection of a range of objects possible. However, it will never be possible to fully eliminate erroneous classifications – one reason the reliability of automatic image processing must continue to improve.
Correct classification of objects is a matter of life or death in autonomous driving, and this requires a deeper understanding of decision-making processes within the neural networks. Gaining a better grasp of these mechanisms is the only way to reduce misclassification to a minimum and comply with the ISO 26262 and ISO/PAS 21448 safety standards for the reduction of, for example, unknown or unsafe scenarios.
That’s why, as part of its research activities, Arrk Engineering has developed the foundations of a framework for better understanding how CNNs work, and ultimately improving their object classification capabilities. This framework makes it easy to identify and eliminate vulnerabilities in a CNN, thus minimizing the risk of errors and accidents caused by incorrect classifications.
“For autonomous driving it is key that the algorithms for object recognition work fast and yield a minimal error rate, but it will only be possible to develop optimal safety features for autonomous driving once we have understood neural networks down to the last detail. The ISO 26262 and ISO/PAS 21448 standards provide the general framework for this, and it will be especially important to ensure the development processes and evaluation metrics are uniform,” explained Václav Diviš, senior engineer for ADAS and autonomous driving at Arrk Engineering.
To achieve this goal, Arrk Engineering has established an evaluation framework for machine learning in the form of software as part of its research activities. This software will enable deeper insight into the recognition process of neural networks. From there, it will be possible to optimize algorithms and improve automatic object recognition. The experiment also served to gain a better understanding of how neural networks work.
 Training the neural network
Training the neural network
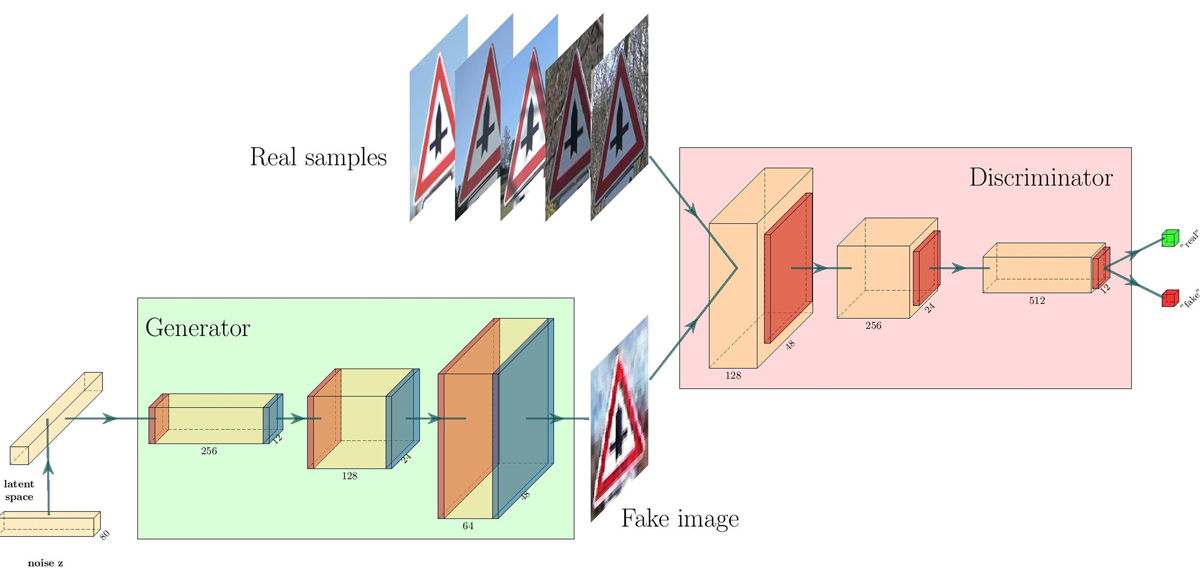
The first step was to select a reliable generative adversarial network (GAN) architecture, consisting of two neural networks – one generator and one discriminator – to provide a basis for the framework and to augment the dataset. In this phase, the used dataset comprised more than 1,000 photos of pedestrians.
“Additional images were generated using the GAN to extend the dataset. The GAN’s generator synthesized an image and the discriminator assessed the quality of this image. The interaction between these two neural networks enables us to extract the features from the original objects, generate a new image, and extend the original dataset relatively easily.”
Then the classification network was trained on the original dataset and the test results were evaluated. To achieve the best possible results, Arrk used state-of-the-art architectures for all elements in the experiment.
“The generalization of the object represents a challenge in image processing. The basic question is: “What defines pedestrian?” This can be easily answered by humans, since we generalize inductively. Neural networks, on the other hand, work deductively and require numerous examples to identify a specific object,” explained Diviš.
Furthermore, it is important to observe ‘corner cases’ – special cases in which pedestrians are not recognized due to a pedestrian’s unusual posture, an obtrusion blocking a sensor’s view, or poor lighting due to weather conditions. Datasets typically lack suitable image material to classify these exceptional cases, but thanks to the GAN structure that has been established, Arrk has managed to supplement the dataset with computer-generated images and thus mitigate this problem.
Optimization of object classification processes
Arrk then began with comprehensive tests to gain a deeper understanding of the processes that underlie CNN training, focusing particularly on the filtering of object attributes as well as the depiction of regions of interest (ROI) in the image area being examined. The emergence of these kernel weights and the resulting ROI are essential for finding evaluation metrics and thus automated object classification. In their analyses, experts looked at a number of processes that occur in neural networks and examined approaches to understand the neurons’ flow of information.
“Some neurons are more associated with the identification of pedestrians and produce stronger responses than others. That’s why we’ve tested a range of scenarios in which we deactivated certain neurons to see how they influence decision-making processes. We could confirm that not every neuron responsible for identifying pedestrians needs to be activated, and in fact not removing some neurons can even lead to quicker and better results.”
The framework that was created can be used to analyze these types of changes.
This enables the stability of algorithms to be sustainably increased, which will serve to make autonomous driving safer. Precautions could be taken, for example, to reduce the risk of an ‘adversary attack’ – the external deployment of a malicious code disguised as a neutral image to compromise the neural network. This code generates a disturbance and influences the decisions of certain neurons, making it impossible to correctly recognize objects. The effects of these types of external disruptions could be reduced by removing inactive neurons, as this would provide fewer targets to attack in the neural network.
Diviš said, “We will never be able to guarantee correct object classification 100% of the time. Our job is to identify and better understand vulnerabilities in neural networks. Only by doing so can we take efficient counteractive measures and ensure maximum safety.”
A system’s object classification capabilities can also be improved immensely through the evaluation and combination of various data collected by sensors such as cameras, lidar and radar.